L'instanciation implicite du format Alembic
Par Narann le vendredi, 23 juin 2017, 23:10 - Infographie 3D - Boulot - Lien permanent
 Suite à la publication de mon post mortem sur Ballerina, certains d’entre vous semblaient intrigués par le paragraphe concernant l’instanciation implicite des fichiers Alembics.
Suite à la publication de mon post mortem sur Ballerina, certains d’entre vous semblaient intrigués par le paragraphe concernant l’instanciation implicite des fichiers Alembics.
Dans ce billet, je vous propose d’aller un peu plus loin avec une explication théorique, un peu de pratique et un peu de code (la recette du bonheur en somme :petrus: ).
Le principe
Dans un fichier Alembic, les géométries sont stockées sous forme de tableaux.:
- Les positions des sommets : [point1.x, point1.y, point1.z, point2.x, point2.y, point2.z, point3.x, …]
- Les nombres de « points par face » (souvent quatre, comme vous pouvez vous en douter): [4, 4, 4, 4, 4, 4, 4, …]
- Les indices de positions par face : [0, 1, 2, 3, 3, 2, 4, 5, …]
Le dernier est le plus subtil à comprendre : Combiné au second, il permet de construire les faces : La face 1 est compose de 4 indices. On prend donc, dans le tableau de position, les indices de position (dernier tableau): 0, 1, 2, 3. La face 2, est compose de 4 indices. On prend donc, dans le tableau d’indice de position, les 4 indices suivants qu’on va chercher dans le tableau des positions : 3, 2, 4, 5. Et ainsi de suite.
C’est un peu bizarre si on n’est pas habitué, mais on stocke très souvent les données géométriques de cette façon et je vais tenter de vous expliquer pourquoi. :hehe:
Vous l’aurez compris, le premier tableau ne concerne que les positions des sommets (vertices en anglais) et les deux seconds tableaux, la topologie de la géométrie. Quand un objet est animé, ce ne sont souvent que ses sommets qui bougent. Sa topologie (l’ordre de ses faces, arêtes et sommets) ne change pas.
Mais comment, quand on exporte de la géométrie image après image, la lib Alembic sait-elle que la topologie n’a pas changée ? C’est la magie des fonctions de hachage.
Histoire de vous éviter la lecture de la page Wikipédia, une fonction de hachage sert, grosso modo, à générer une signature numérique (qui ressemble vaguement à « 867fc32883baaa34 ») depuis une suite de bit.
Comme vous vous en doutez, la suite de bit en question, ce sont nos tableaux. En langage bas niveau (C++ en l’occurrence), un tableau est une suite de valeur fortement typées. Un chiffre flottant se stocke sur 32 bits. Une position se stocke sur 3 chiffres flottants (x, y, z), soit 3x32=96bits. Pour 8 positions (un cube) il faut donc 8x96=768bits. Ce sont ces 768bits que la fonction de hachage (Spooky de son petit nom) va ingurgiter pour nous sortir une valeur bizarre (eg. « 867fc32883baaa34 »): La signature numérique du tableau de position. Si on renvoie le même tableau (avec des positions parfaitement identiques), on a la même signature.
Vous venez juste de vous farcir un cours de science informatique en vitesse de la lumière la ! :hihi:
Dans un Alembic, chaque tableau possède donc sa signature numérique.
À chaque fois que vous envoyez un nouveau tableau à Alembic (pour chaque image en fait), ce dernier calcule sa signature numérique (son hash). S’il est déjà présent dans le fichier, il ne l’ajoute pas au fichier mais précise simplement que l’image en question utilise le tableau avec le hash que vous venez de calculer.
Avec ce système on peut avoir plusieurs tableaux contenant la position des sommets animés (un par image en fait) tout en gardant les deux tableaux de topologie unique pour tout le fichier.
Pour résumer, si vous exporter l’animation d’un simple cube déformé sur 10 images vous aurez :
- 10 tableaux de position (un par image)
- 1 tableau de point par face (celui de la première image, réutilise sur toutes les images)
- 1 tableau de position par face (celui de la première image, réutilise sur toutes les images)
Pour les plus curieux d’entre vous, voici la ligne de code de l’exporteur Alembic de Maya qui s’occupe d’envoyer les différents tableaux que je vous ai présenté ci-dessus dans un fichier Alembic. Notez que l’exporteur ne fait aucune distinction. Pour chaque image, il envoie tout à l’Alembic et c’est ce dernier qui décide de stocker les tableaux dans le fichier ou non.
Une fois qu’on a un beau fichier tout optimisé qu’est ce qui se passe ?
Et bien quand l’application (un moteur de rendu par exemple) demande, les tableaux de l’image 5 à un fichier Alembic, ce dernier (enfin le code de la lib Alembic) renvoi le tableau de position de l’image 5, puis les deux tableaux de la topologie de la première image.
Notez que je ne vous ai pas parlé des UVs, normals, vertex color, etc. Mais sachez que le concept est le même que pour les positions et la topologie.
Et les instances implicites là-dedans ?
J’arrive au dernier point, celui qui devrait vous faire tilter. :idee:
En plus de stocker de la géométrie, Alembic stock aussi la hiérarchie. Un transform est un objet présenté sous la forme de translation, rotation, échelle et dont la représentation mathématique est une matrice 4 × 4 (je ne rentre pas dans les détails mais sachez que quand vous manipulez un transform, vous manipulez en fait une matrice). Une hiérarchie de transform est donc une hiérarchie de matrice.
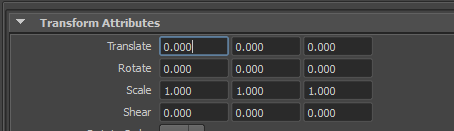
Derrière les paramètres que vous manipulez tous les jours se cache un objet mathématique bien cool : La matrice ! :youplaBoum:
Au même titre que pour les tableaux de position et de topologie, les matrices peuvent être animée par image (quand on anim un simple déplacement qui ne déforme pas la géométrie de l’objet)
Notez que dans mon exemple précédant, j’ai précisé qu’il s’agissait d’un cube déformé. L’animation ne se situait donc pas sur le transform du cube mais directement sur les sommets (c’est la géométrie qui bouge à chaque image, comme un personnage skinné en fait).
Sauf que si, au lieu de déformer l’objet, vous n’animer que son transform (translation, rotation, échelle), le tableau des positions des sommets ne change pas d’une image à l’autre, seule le transform parent de la shape (la matrice parent) change.
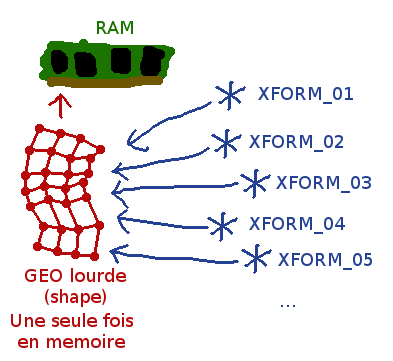
Ce qui veut dire (arriver ici vous devriez l’avoir compris) que si un modeleur duplique des centaines d’objets sans les modifier puis exporte un Alembic, les sommets et topologies des objets ne sont stockés qu’une seule fois dans le fichier et seul la position des matrices (différentes pour chaque objet) sont stockés de manière individuelle. Et ça, c’est la définition d’une instance géométrique !
Je reprends un schéma que j’avais utilisé pour expliquer le principe des instances Maya (c’est pas super adapté mais ça représente bien le principe):
Un exemple concret
Comme je sais que vous ne me croyez pas, je vous propose un exemple concret à l’aide de Maya. :siffle:
Créez une sphère :

Subdivisez-la histoire qu’on puisse voir des différences de poids facilement lors de l’export :

Quatre, c’est très bien :
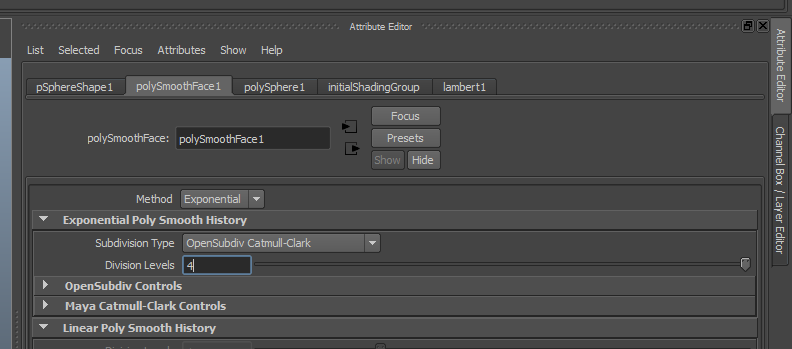

:trollface:
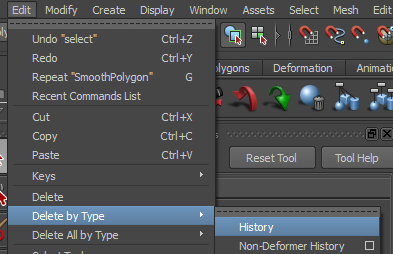
Détruisez l’historique afin de ne garder que la shape :
C’est parti ! Dupliquez ça plusieurs fois :

Notez qu’il ne s’agit en aucun cas d’instances Maya au sens propre. Ce sont de simples duplications. Notez aussi comment, malgré le poids de la géométrie, Maya reste réactif. Je soupçonne en effet que ce dernier utilise aussi l’instance implicite quand on fait des duplications et ne duplique la géométrie de chaque objet en mémoire qu’une fois qu’on commence à modifier l’objet. :reflechi:
Mais on ne s’arrête pas ! :grenadelauncher:

C’est pas mal, maintenant on exporte tout ça :
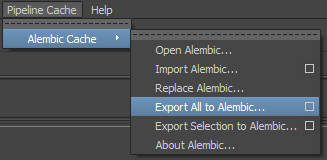
Une seule image (vous pourrez refaire le test sur un range plus large, ça ne changera pas grand-chose):
Pas besoin des normales ni des UVs :
Puis validez (ou exécutez cette commande MEL):
AbcExport -j "-frameRange 1 1 -dataFormat ogawa -file /home/narann/test/test1.abc";
L’export devrait être assez rapide. Chez moi, le fichier fait 3.12Mo. Clairement, toute la géométrie n’est pas stockée. C’est parce qu’Alembic a reconnu que toutes les sphères étaient identiques. Les données qui composent sa géométrie (tableau de position des sommets et topologie) ne sont donc stockées qu’une seule fois, le reste étant des transforms (matrices) pointant vers la même géométrie. :redface:
Mais peut-être qu’avec 3.12Mo vous n’êtes toujours pas convaincu. Peut-être que 105 sphères subdivise à 4 ça ne pèse que 3.12Mo après tout… :perplex:
On va donc faire un truc qui est très souvent fait en production, un truc souvent demande par le rig pour plein de bonnes raisons : On va réinitialiser les transforms. Sélectionnez tout :

Faites un "Freeze Transformations":
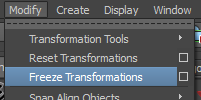
Les valeurs des positions sont donc revenus à 0 mais les centres géométriques des objets n’ont pas bouge. C’est dû au fait que Maya permet de désolidariser le point de pivot de l’objet par rapport au centre géométrique.
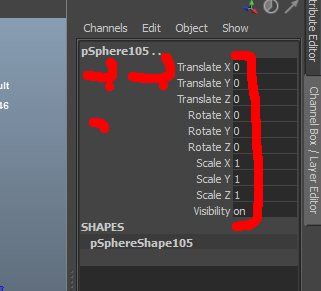
On va donc faire un "Reset Transformations" :
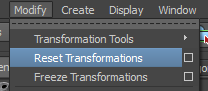
Celui-ci vient modifier les valeurs géométriques de tous les sommets pour qu’ils correspondent au point de pivot. Dans notre cas, chaque objet a maintenant son transform ainsi que son centre géométrique au centre de la scène :
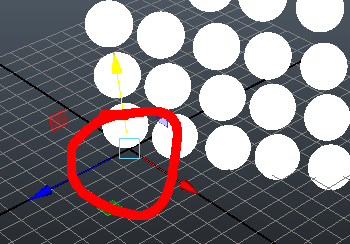
Cela veut dire que chaque sommet de chaque sphère possède une position identique à sa position dans le monde (0, 0, 0). Chaque sommet ayant une position unique par rapport à son centre géométrique, on a donc perdu toute forme d’instanciation implicite pour Alembic. Mais qu’a cela ne tienne, testez pas vous-même :
AbcExport -j "-frameRange 1 1 -dataFormat ogawa -file /home/narann/test/test2.abc";
Chez moi, le fichier fait 121Mo. :siffle: Chaque sphère possède ses propres tableaux de position de sommet. En principe les tableaux de topologie sont instanciés car notre petite manipulation des points de pivot n’a pas change la topologie. Si on modifiait la topologie aléatoirement pour chaque sphère, le fichier aurait été encore plus gros.
Bon, on a deux fichiers, il serait peut-être temps de les tester dans nos moteurs de rendu favoris pour savoir ce qu’il en est.
Dans Guerilla
Je vais tester dans Guerilla car c’est avec lui que je suis le plus à l’aise et il dispose d’un bon retour pour savoir si l’Alembic est correctement interprété.
Importez votre premier Alembic. Les applications étant souvent friandes de moyen d’optimiser le chargement des fichiers, elles s’appuient sur l’instanciation implicite que leur propose Alembic (comme expliqué dans le post mortem, ce fut flagrant sur Mari). Guerilla n’y échappe pas et c’est assez rapide :

Avant de faire le premier rendu, activez la Verbosity à Diagnostics puis cochez Diagnostic Shapes et Diagnostic Accelerator:
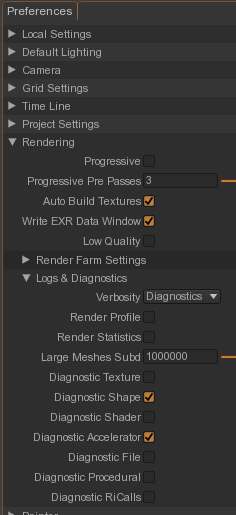
Puis faites un rendu. Voici le log :
06/19/2017 15:36:48 RNDR DIA: hash for 'test:pSphere61|test:pSphereShape61' is 867fc32883baaa34:60c4e1c779f31ee
06/19/2017 15:36:48 RNDR DIA: build accel 'test:pSphere61|test:pSphereShape61'
06/19/2017 15:36:48 SHAP DIA: loaded shape '/home/narann/test/test1.abc' '/pSphere61/pSphereShape61.RenderGeometry'
06/19/2017 15:36:48 SHAP DIA: P float3[99842] min=(-0.979728,-0.997817,-0.979728) max=(0.979728,0.997817,0.979728)
06/19/2017 15:36:48 SHAP DIA: N float3[99842] min=(-1.000000,-1.000000,-1.000000) max=(1.000000,1.000000,1.000000)
06/19/2017 15:36:48 MBVH DIA: Building triangle accelerator for 'test:pSphere61|test:pSphereShape61'
06/19/2017 15:36:48 MBVH DIA: Built accelerator for 'test:pSphere61|test:pSphereShape61', 199680 triangles, 8.81M (geo 3.81M, tree 5.00M)
06/19/2017 15:36:48 RNDR DIA: hash for 'test:pSphere62|test:pSphereShape62' is 867fc32883baaa34:60c4e1c779f31ee
06/19/2017 15:36:48 BRDF DIA: hash for 'test:pSphere76|test:pSphereShape76' is 867fc32883baaa34:60c4e1c779f31ee
06/19/2017 15:36:48 BRDF DIA: hash for 'test:pSphere49|test:pSphereShape49' is 867fc32883baaa34:60c4e1c779f31ee
06/19/2017 15:36:48 BRDF DIA: hash for 'test:pSphere33|test:pSphereShape33' is 867fc32883baaa34:60c4e1c779f31ee
06/19/2017 15:36:48 BRDF DIA: hash for 'test:pSphere18|test:pSphereShape18' is 867fc32883baaa34:60c4e1c779f31ee
06/19/2017 15:36:48 BRDF DIA: hash for 'test:pSphere48|test:pSphereShape48' is 867fc32883baaa34:60c4e1c779f31ee
...
Comme vous pouvez le constater, la shape n’est chargée qu’une seule fois (loaded shape dans le log) puis Guerilla s’appuie sur le hash, toujours identique, pour placer les autres sphères.
Si vous changez de fichier Alembic et que vous relancez le rendu, vous constaterez que le message de chargement de la shape « loaded shape » s’applique pour chaque sphère du fichier et que le rendu met plus de temps avant de démarrer.
Là ou c’est intéressant (et je suis sûr que tous les autres moteurs le font) c’est que quand Guerilla charge plusieurs Alembic, il instancie entre fichier. Si un modeleur a utilisé deux objets identiques dans deux Alembic différents, Guerilla le remarque et ne le charge qu’une fois en mémoire. Forcément, quand tes bâtiments ne sont que des variantes de silhouette utilisant des objets géométriques identiques c’est du pain béni pour le moteur.
Comment permettre aux modeleurs de savoir quand deux objets vont être instancie dans un Alembic ?
Si vous ne connaissez pas Python, vous risquez d’être un peu perdu sur cette dernière partie, je préfère vous prévenir. :)
Sur Ballerina nous avions une commande développée en externe qui nous permettait d’avoir le même hash que ceux qui allaient être mis généré par l’Alembic. C’est assez difficile à faire et mon but c’est de vous mettre le pied à l’étrier.
Je vous propose deux code :
- Un très simple, à base de commande Python qui ne s’occupe que des sommets.
- Un autre, plus compliqué, faisant des appels à l’API Maya en Python mais qui prend en compte les UVs.
Bien entendu, ce sont des codes que j’ai fais chez moi sur des scènes cubes et sphère mais absolument pas teste en production. À vous de voir ce qu’ils valent.
En commande Maya
Voici le premier code :
import collections
import maya.cmds as mc
h_vtx = collections.defaultdict(set)
for shp in mc.ls(type='mesh'):
h = hash(tuple(mc.xform(shp+'.vtx[*]', query = True, objectSpace = True, translation = True)))
h_vtx[h].add(shp)
Et l’explication ligne à ligne :
h_vtx = collections.defaultdict(set)
On crée d’abords un dictionnaire (defaultdict, qui permet d’ajouter un objet, ici un set, à la volée):
- Les clefs seront les hash des positions des sommets (comme 14653146579)
- Les valeurs un set() de shape correspondant au hash en clef (comme set('|pSphere1|pSphereShape1', '|pSphere2|pSphereShape2'))
for shp in mc.ls(type='mesh'):
Via cette boucle nous allons traverser toutes les shapes de type mesh de la scène.
h = hash(tuple(mc.xform(shp+'.vtx[*]', query = True, objectSpace = True, translation = True)))
Il y a plusieurs commandes empaquetées ici :
- mc.xform() renvoi la position des sommets en espace objet.
- tuple() permet d’avoir une séquence immutable ordonnée à partir de laquelle on pourra générer un hash (plus d’info ici).
- hash() permet de générer une signature depuis une variable (la liste des positions des sommets).
On stocke le hash dans la variable… « h ».
h_vtx[h].add(shp)
Ici on ajoute la shape à la liste des shapes ayant le même hash que celui trouvé précédemment.
Imaginons une scène qui ressemble à ça (juste des sphères dupliquées avec une, au centre, dont j’ai bouge un vertex):
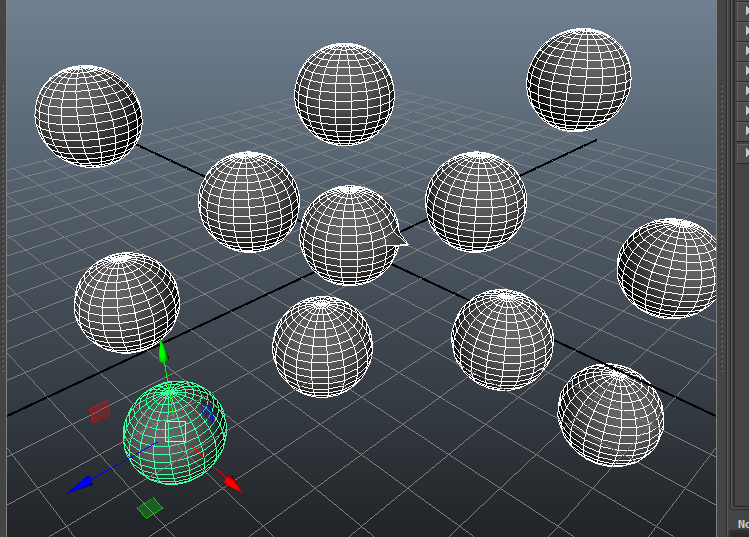
Si on exécute ce bout de code et qu’on print "h_vtx" on obtient :
# Result: defaultdict(<type 'set'>, {-1145497079: set([u'pSphereShape9', u'pSphereShape3', u'pSphereShape2', u'pSphereShape1', u'pSphereShape10', u'pSphereShape7', u'pSphereShape6', u'pSphereShape5', u'pSphereShape4', u'pSphereShape12', u'pSphereShape11']), 1873436783: set([u'pSphereShape8'])}) #
Le dictionnaire montre deux hashes (-1145497079 et 1873436783), le dernier n’ayant qu’une sphère, celle dont le vertex a été bouge. Vous pouvez sélectionner les sphères du premier groupe :
mc.select(list(h_vtx[h_vtx.keys()[0]]))
Modifiez 0 par 1 pour sélectionner la sphère du second groupe.
Dès lors, vous pouvez commencer à expérimenter : Dupliquer la sphère du centre (celle avec un vertex en vrac) plusieurs fois puis réexécutez le code et voyez comment il reconnait, dans le dictionnaire « h_vtx », les sphères identiques. Ensuite, faite une autre modification sur une sphère puis réexécutez le code et voyez comment cette sphère dispose maintenant de son propre hash.
Dans tous les cas, vous remarquerez que le script les regroupe bien qu’il ne s’agisse pas d’instances réelles Maya.
Arrivez ici.
En utilisant l’API Maya
Ici c’est un peu plus compliqué, mais on se rapproche beaucoup plus de ce que fait Alembic :
import maya.OpenMaya as om
sel = om.MSelectionList()
om.MGlobal.getActiveSelectionList(sel)
fn_meshes = []
for i in xrange(sel.length()):
dag_path = om.MDagPath()
sel.getDagPath(i, dag_path)
fn_mesh = om.MFnMesh(dag_path)
fn_meshes.append((fn_mesh.fullPathName(), fn_mesh))
# on aurait pu ajouter les normals, les crease edges, les colors mais osef
h_pt = {}
h_vtx_counts = {}
h_vtx_ids = {}
h_uv_counts = {}
h_uv_ids = {}
h_uvs = {}
for full_path, fn_mesh in fn_meshes:
# vertex positions
pts = om.MPointArray()
fn_mesh.getPoints(pts)
h = hash(tuple((pts[i].x, pts[i].y, pts[i].z) for i in xrange(pts.length())))
h_pt[full_path] = h
# vertex topology
vtx_counts = om.MIntArray()
vtx_ids = om.MIntArray()
fn_mesh.getVertices(vtx_counts, vtx_ids)
h = hash(tuple(vtx_counts[i] for i in xrange(vtx_counts.length())))
h_vtx_counts[full_path] = h
h = hash(tuple(vtx_ids[i] for i in xrange(vtx_ids.length())))
h_vtx_ids[full_path] = h
# uv positions
uv_us = om.MFloatArray()
uv_vs = om.MFloatArray()
fn_mesh.getUVs(uv_us, uv_vs)
assert uv_us.length() == uv_vs.length()
h = hash(tuple((uv_us[i], uv_vs[i]) for i in xrange(uv_us.length())))
h_uvs[full_path] = h
# uv topology
uv_counts = om.MIntArray()
uv_ids = om.MIntArray()
fn_mesh.getAssignedUVs(vtx_count, vtx_list)
h = hash(tuple(uv_counts[i] for i in xrange(uv_counts.length())))
h_uv_counts[full_path] = h
h = hash(tuple(uv_ids[i] for i in xrange(uv_ids.length())))
h_uv_ids[full_path] = h
# the hash of the hashes
h_total = {}
for full_path in h_pt.keys():
h_total[full_path] = hash((h_pt[full_path],
h_vtx_counts[full_path],
h_vtx_ids[full_path],
h_uvs[full_path],
h_uv_counts[full_path],
h_uv_ids[full_path]))
path_per_h = collections.defaultdict(set)
for full_path, h in h_total.iteritems():
path_per_h[h].add(full_path)
print path_per_h
mc.select(list(path_per_h[path_per_h.keys()[1]]))
Pas de panique, voici l’explication ligne à ligne.
import maya.OpenMaya as om
sel = om.MSelectionList()
om.MGlobal.getActiveSelectionList(sel)
Comme je n’aime pas les longs espace de nom, j’importe OpenMaya sous l’espace de nom "om". :seSentCon:
Ensuite, on fabrique une MSelectionList qui est une sorte de « liste spécialement adaptée à la sélection ». Et on appelle une commande globale bien pratique qui récupère la sélection.
TL;DR: On fait l’équivalent de mc.ls(). avec plus de lignes. :baffed:
fn_meshes = []
for i in xrange(sel.length()):
dag_path = om.MDagPath()
sel.getDagPath(i, dag_path)
fn_mesh = om.MFnMesh(dag_path)
fn_meshes.append((fn_mesh.fullPathName(), fn_mesh))
Avec cette boucle, on va récupérer les MFnMesh de chacun des mesh de notre sélection. Un MFnMesh est un « ensemble de fonction » (Function set, préfixé MFn dans l’API Maya) qui permet de lier des fonctions sur des données (C’est un peu technique mais dans l’API Maya, les nœuds sont simplement des données compatibles avec certains ensemble de fonction).
dag_path = om.MDagPath()
sel.getDagPath(i, dag_path)
On crée un MDagPath vide qu’on remplit avec l’item de la sélection (« i » de la boucle). Un MDagPath est un « chemin vers un nœud hiérarchisé ».
fn_mesh = om.MFnMesh(dag_path)
Maintenant qu’on a un chemin direct, on récupère l’ensemble de fonction.
fn_meshes.append((fn_mesh.fullPathName(), fn_mesh))
Enfin, on l’ajoute à la liste sous la forme un tuple de deux éléments (le chemin du nœud et l’ensemble de fonction).
On avance dans le script pour la seconde boucle :
# on aurait pu ajouter les normals, les crease edges, les colors mais osef
h_pt = {}
h_vtx_counts = {}
h_vtx_ids = {}
h_uv_counts = {}
h_uv_ids = {}
h_uvs = {}
Ici on prépare simplement des dictionnaires de hash. Ils sont tous préfixés d’un « h_ » parce qu’ils contiennent des…? Hash bien-sur ! Vous regrettez déjà de ne pas avoir fais math sup’ math spé’ je le sais. Que voulez-vous, certains réussissent et d’autres écrivent un blog. :baffed:
Bref, la clef de chacun des dictionnaires sera le chemin complet d’un nœud, et la valeur, sa valeur de hash. Un peu comme ceci :
h_pt = {'|pSphere1|pSphereShape1': 1574633,
'|pSphere2|pSphereShape2': 1574633,
'|pSphere3|pSphereShape3': 1657615,
...}
- « h_pt » contiendra les hash des tableaux de la position des sommets
- « h_vtx_counts » contiendra les hash des tableaux du nombre de sommet par face
- « h_vtx_ids » contiendra les hash des tableaux des indices des sommets
Et pareil pour les uvs… :sourit:
Notez que je me suis arrêté à la géométrie et aux UVs, mais on aurait pu ajouter les normales, les couleurs par sommet, etc. Simplement que comme on ne les exporte pas avec l’Alembic : On s’en fout ! :dentcasse:
C’est parti pour la boucle principale (qui est en fait compose de plusieurs blocs assez similaires.
for full_path, fn_mesh in fn_meshes:
On déroule la boucle, pour chaque chemin complet d’un nœud on a son ensemble de fonction.
# vertex positions
pts = om.MPointArray()
fn_mesh.getPoints(pts)
h = hash(tuple((pts[i].x, pts[i].y, pts[i].z) for i in xrange(pts.length())))
h_pt[full_path] = h
On fabrique un MPointArray() (un tableau de… MPoint()) nommé "pts", qu’on remplit avec les points du mesh via la méthode getPoints() de l’ensemble de fonction "fn_mesh".
Ensuite, on déroule les valeurs de chaque point dans un itérateur qu’on déroule à son tour, comme le script précédant, dans un tuple() dont on génère le hash.
La raison pour laquelle on déroule la position des points c’est qu’un MPointArray() n’est pas hashable par python. Il faut donc générer une structure en pur python sinon, dans mon cas, hash renvoi toujours la même valeur, indépendamment du contenu du MPointArray(). :slowclap:
Et la dernière ligne stock le hash pour le chemin complet du nœud.
Et le reste de la boucle c’est tout pareil ! :hehe:
Ne change que le type des tableaux (MIntArray() et MFloatArray()) ainsi que les méthodes pour récupérer les informations (getVertices(), getUVs(), getAssignedUVs()).
Juste un petit assert (que j’utilise souvent) pour expliquer que je m’attends à ce que le tableau contenant les valeurs de U et de V fassent la même taille.
On passe à la suite :
# the hash of the hashes
h_total = {}
for full_path in h_pt.keys():
h_total[full_path] = hash((h_pt[full_path],
h_vtx_counts[full_path],
h_vtx_ids[full_path],
h_uvs[full_path],
h_uv_counts[full_path],
h_uv_ids[full_path]))
Viens l’avant-dernière boucle qui consiste, comme le commentaire l’indique, à générer le « hash des hash ». En effet, bien qu’on ait séparé les hashes par type de tableau (position des sommets, topologie, UVs), ce qui peut être très utile pour mettre le doigt sur les parties qui ne s’accommode pas aux autres, je vous propose de générer un hash final, par nœud.
On génère donc un itérateur avec tous les hash, qu’on envoie dans un hash.
Et pour finir :
path_per_h = collections.defaultdict(set)
for full_path, h in h_total.iteritems():
path_per_h[h].add(full_path)
On inverse notre dictionnaire avec, en guise de clef, le hash et en guise de valeur, un set() des chemins des nœuds avec ce hash. Ce qui nous donne un dictionnaire qui ressemble à ça :
h_pt = {1574633: set(['|pSphere1|pSphereShape1',
'|pSphere2|pSphereShape2']),
1657615: set(['|pSphere3|pSphereShape3',
...}
Et on peut sélectionner les nœuds par hash comme ça :
mc.select(list(path_per_h[path_per_h.keys()[1]]))

Conclusion
J’espère que le principe des instances implicites des fichiers Alembics est plus clair pour vous maintenant. Si vous êtes à l’aise en script, je vous invite à essayer de structurer ces informations dans une petite interface de sélection pour aider vos modeleurs. Ce n’est pas un petit boulot mais sur un projet un peu ambitieux ça peut valoir le coup.
:marioCours:
Édit du 25 juin 2017 : J’ai bien conscience que ce billet est assez technique, surtout sa première partie. S’il y a des points qui vous semblent mal expliqués, n’hésitez pas à m’en faire part dans les commentaires, j’essaierai de peaufiner mes explications.